Machine Learning for Computer Graphics
- By-example content creation: textures, materials and appearance
- Computational Photography and image analysis
- 3D appearance modeling and rendering
- Perception for image synthesis





 Presented by K. Vanhoey at the Eurographics 2022 Conference (short papers), April 25-29, 2022.
Presented by K. Vanhoey at the Eurographics 2022 Conference (short papers), April 25-29, 2022.
We observe that a Loop refinement step invariably splits halfedges into four new ones. We leverage this observation to formulate a breadth-first uniform Loop subdivision algorithm: Our algorithm iterates over halfedges to both generate the refined topological information and scatter contributions to the refined vertex points. Thanks to this formulation we limit concurrent data access, enabling straightforward and efficient parallelization on the GPU. We provide an open-source GPU implementation that runs at state-of-the-art performances and supports production-ready assets, including borders and semi-sharp creases.
 Computer Graphics Forum Vol. 40 issue 8. (Proceedings of the High Performance Graphics 2021 conference (top 30%)
Presented by J. Dupuy at the 2021 Conference on High Performance Graphics (HPG), July 6-9, 2021.
Computer Graphics Forum Vol. 40 issue 8. (Proceedings of the High Performance Graphics 2021 conference (top 30%)
Presented by J. Dupuy at the 2021 Conference on High Performance Graphics (HPG), July 6-9, 2021.
We show that Catmull-Clark subdivision induces an invariant one-to-four refinement rule for halfedges that reduces to simplealgebraic expressions. This has two important consequences. First, it allows to refine the halfedges of the input mesh, whichcompletely describe its topology, concurrently in breadth-first order. Second, it makes the computation of the vertex pointsstraightforward as the halfedges provide all the information that is needed. We leverage these results to derive a novel parallelimplementation of Catmull-Clark subdivision suitable for the GPU. Our implementation supports non-quad faces, extraordinaryvertices, boundaries and semi-sharp creases seamlessly. Moreover, we show that its speed scales linearly with the number ofprocessors, and yields state-of-the-art performances on modern GPUs
In proceedings of the 2021 Conference on Computer Vision and Pattern Recognition (CVPR).
Acceptance rate: 27%.
Presented by K. Vanhoey at the 2021 Conference on Computer Vision and Pattern Recognition (CVPR) conference, June 19-25, 2021.
We address the problem of computing a textural loss based on the statistics extracted from the feature activations of a convolutional neural network optimized for object recognition (e.g. VGG-19). The underlying mathematical problem is the measure of the distance between two distributions in feature space. The Gram-matrix loss is the ubiquitous approximation for this problem but it is subject to several shortcomings. Our goal is to promote the Sliced Wasserstein Distance as a replacement for it. It is theoretically proven,practical, simple to implement, and achieves results that are visually superior for texture synthesis by optimization or training generative neural networks.


Deep Learning is now powering numerous AI technologies in daily life, and convolutional neural networks (CNNs) can apply complex treatments to images at high speeds. At Unity, we aim to propose seamless integration of CNN inference in the 3D rendering pipeline. Unity Labs, therefore, works on improving state-of-the-art research and developing an efficient neural inference engine called Barracuda. In this post, we experiment with a challenging use case: multi-style in-game style transfer.
 Presented by A. Saint-Denis at
High Performance Graphics 2019, July 1-3 2019, Strasbourg, France
Presented by A. Saint-Denis at
High Performance Graphics 2019, July 1-3 2019, Strasbourg, France
We investigate how to take advantage of modern neural style transfer techniques to modify the style of video games at runtime. Recent style transfer neural networks are pre-trained, and allow for fast style transfer of any style at runtime. However, a single style applies globally, over the full image, whereas we would like to provide finer authoring tools to the user. In this work, we allow the user to assign styles (by means of a style image) to various physical quantities found in the G-buffer of a deferred rendering pipeline, like depth, normals, or object ID. Our algorithm then interpolates those styles smoothly according to the scene to be rendered: e.g., a different style arises for different objects, depths, or orientations.

 (Supplemental material here)
Computer Graphics Forum. (Proceedings of Pacific Graphics 2018)
Presented by L. Lettry at the Pacific Graphics 2018 conference, October 8-11, 2018, Hong Kong, Hong Kong.
(Supplemental material here)
Computer Graphics Forum. (Proceedings of Pacific Graphics 2018)
Presented by L. Lettry at the Pacific Graphics 2018 conference, October 8-11, 2018, Hong Kong, Hong Kong.
Machine learning based Single Image Intrinsic Decomposition (SIID) methods decompose a captured scene into its albedo and shading images by using the knowledge of a large set of known and realistic ground truth decompositions. Collecting and annotating such a dataset is an approach that cannot scale to sufficient variety and realism. We free ourselves from this limitation by training on unannotated images. Our method leverages the observation that two images of the same scene but with different lighting provide useful information on their intrinsic properties: by definition, albedo is invariant to lighting conditions, and cross-combining the estimated albedo of a first image with the estimated shading of a second one should lead back to the second one’s input image. We transcribe this relationship into a siamese training scheme for a deep convolutional neural network that decomposes a single image into albedo and shading. The siamese setting allows us to introduce a new loss function including such cross-combinations, and to train solely on (time-lapse) images, discarding the need for any ground truth annotations. As a result, our method has the good properties of i) taking advantage of the time-varying information of image sequences in the (pre-computed) training step, ii) not requiring ground truth data to train on, and iii) being able to decompose single images of unseen scenes at runtime. To demonstrate and evaluate our work, we additionally propose a new rendered dataset containing illumination-varying scenes and a set of quantitative metrics to evaluate SIID algorithms. Despite its unsupervised nature, our results compete with state of the art methods, including supervised and non data-driven methods.
 (project page)
Presented at the New Trends in Image Restoration and Enhancement workshop
and challenges on super-resolution, dehazing, and spectral reconstruction 2018 workshop (NTIRE) at CVPR, June 18th, 2018, Salt Lake City, UT, USA.
In proceedings of Computer Vision and Pattern Recognition 2018.
(project page)
Presented at the New Trends in Image Restoration and Enhancement workshop
and challenges on super-resolution, dehazing, and spectral reconstruction 2018 workshop (NTIRE) at CVPR, June 18th, 2018, Salt Lake City, UT, USA.
In proceedings of Computer Vision and Pattern Recognition 2018.
Low-end and compact mobile cameras demonstrate limited photo quality mainly due to space, hardware and budget constraints. In this work, we propose a deep learning solution that translates photos taken by cameras with limited capabilities into DSLR-quality photos automatically. We tackle this problem by introducing a weakly supervised photo enhancer (WESPE) - a novel image-to-image Generative Adversarial Network-based architecture. The proposed model is trained by under weak supervision: unlike previous works, there is no need for strong supervision in the form of a large annotated dataset of aligned original/enhanced photo pairs. The sole requirement is two distinct datasets: one from the source camera, and one composed of arbitrary high-quality images that can be generally crawled from the Internet - the visual content they exhibit may be unrelated. In this work, we emphasize on extensive evaluation of obtained results. Besides standard objective metrics and subjective user study, we train a virtual rater in the form of a separate CNN that mimics human raters on Flickr data and use this network to get reference scores for both original and enhanced photos. Our experiments on the DPED, KITTI and Cityscapes datasets as well as pictures from several generations of smartphones demonstrate that WESPE produces comparable or improved qualitative results with state-of-the-art strongly supervised methods.
 (Supplemental material here and here:
)
In proceedings of the IEEE Winter Conference on Applications of Computer Vision 2018 conference.
Acceptance rate: 45%.
Presented by L. Lettry at the IEEE Winter Conference on Applications of Computer Vision 2018 conference, March 12-15, 2018, Lake Tahoe, California, USA.
(Supplemental material here and here:
)
In proceedings of the IEEE Winter Conference on Applications of Computer Vision 2018 conference.
Acceptance rate: 45%.
Presented by L. Lettry at the IEEE Winter Conference on Applications of Computer Vision 2018 conference, March 12-15, 2018, Lake Tahoe, California, USA.
We present a new deep supervised learning method for intrinsic decomposition of a single image into its albedo and shading components. Our contributions are based on a new fully convolutional neural network that estimates absolute albedo and shading jointly. Our solution relies on a single end-to-end deep sequence of residual blocks and a perceptually-motivated metric formed by two adversarially trained discriminators. As opposed to classical intrinsic image decomposition work, it is fully data-driven, hence does not require any physical priors like shading smoothness or albedo sparsity, nor does it rely on geometric information such as depth. Compared to recent deep learning techniques, we simplify the architecture, making it easier to build and train, and constrain it to generate a valid and reversible decomposition. We rediscuss and augment the set of quantitative metrics so as to account for the more challenging recovery of non scale-invariant quantities. We train and demonstrate our architecture on the publicly available MPI Sintel dataset and its intrinsic image decomposition, show attenuated overfitting issues and discuss generalizability to other data. Results show that our work outperforms the state of the art deep algorithms both on the qualitative and quantitative aspect.
 First presented at the French workshop on Computational Photography, November 13th, 2018.
First presented at the French workshop on Computational Photography, November 13th, 2018.
In 2012, an old and impopular algorithm is the basis of a major breakthrough on the ImageNet classification benchmark: artificial neural networks.
We're at the edge of the "deep learning era".
Since then, this method allowed machines to beat humans at numerous tasks, including image analaysis and processing.
Many domains of computer science, including computer graphics, are impacted, and in particular computational photography.
The rankings of best-performing algorithms on superresolution, colorisation, inpainting, and many other tasks are all (or nearly all) lead by deep learning.
So: temporary hype or miracle solution to all problems in computational photography?
By putting aside any dogmatic conceptions on this topic, this presentation has the objective to take a step back on recent methods and initiate thoughts and discussion about it.
We'll broadly overview a list of applications of computational photography, then will seek through analysis of several solutions to define a class of problems that are easily, not so easily, or impossibly solved by usage of deep learning, respectively.
 (Supplemental material here)
ACM Transactions on Applied Perception, vol. 15, issue 1 (October 2017).
(Supplemental material here)
ACM Transactions on Applied Perception, vol. 15, issue 1 (October 2017).
Geometric modifications of 3D digital models are commonplace for the purpose of efficient rendering or compact storage. Modifications imply visual distortions which are hard to measure numerically. They depend not only on the model itself but also on how the model is visualized. We hypothesize that the model’s light environment and the way it reflects incoming light strongly influences perceived quality. Hence, we conduct a perceptual study demonstrating that the same modifications can be masked, or conversely highlighted, by different light-matter interactions. Additionally, we propose a new metric that predicts the perceived distortion of 3D modifications for a known interaction. It operates in the space of 3D meshes with the object’s appearance, i.e. the light emitted by its surface in any direction given a known incoming light. Despite its simplicity, this metric outperforms 3D mesh metrics and competes with sophisticated perceptual image-based metrics in terms of correlation to subjective measurements. Unlike image-based methods, it has the advantage of being computable prior to the costly rendering steps of image projection and rasterization of the scene for given camera parameters.
 (project page)
Presented by A. Ihnatov at the International Conference on Computer Vision 2017 (ICCV), October 22-29, 2017, Venice, Italy.
In proceedings of the International Conference on Computer Vision 2017.
(project page)
Presented by A. Ihnatov at the International Conference on Computer Vision 2017 (ICCV), October 22-29, 2017, Venice, Italy.
In proceedings of the International Conference on Computer Vision 2017.
Despite a rapid rise in the quality of built-in smartphone cameras, their physical limitations - small sensor size, compact lenses and the lack of specific hardware, -- impede them to achieve the quality results of DSLR cameras. In this work we present an end-to-end deep learning approach that bridges this gap by translating ordinary photos into DSLR-quality images. We propose learning the translation function using a residual convolutional neural network that improves both color rendition and image sharpness. Since the standard mean squared loss is not well suited for measuring perceptual image quality, we introduce a composite perceptual error function that combines content, color and texture losses. The first two losses are defined analytically, while the texture loss is learned in an adversarial fashion. We also present DPED, a large-scale dataset that consists of real photos captured from three different phones and one high-end reflex camera. Our quantitative and qualitative assessments reveal that the enhanced image quality is comparable to that of DSLR-taken photos, while the methodology is generalized to any type of digital camera.
 (Supplemental material here)
Presented by L. Lettry at the IEEE Winter Conference on Applications of Computer Vision 2017 conference, March 27-29, 2017, Santa Rosa, California, USA.
(Supplemental material here)
Presented by L. Lettry at the IEEE Winter Conference on Applications of Computer Vision 2017 conference, March 27-29, 2017, Santa Rosa, California, USA.
We propose a new approach for detecting repeated patterns on a grid in a single image. To do so, we detect repetitions in the space of pre-trained deep CNN filter responses at all layer levels. These encode features at several conceptual levels (from low-level patches to high-level semantics) as well as scales (from local to global). As a result, our repeated pattern detector is robust to challenging cases where repeated tiles show strong variation in visual appearance due to occlusions, lighting or background clutter. Our method contrasts with previous approaches that rely on keypoint extraction, description and clustering or on patch correlation. These generally only detect low-level feature clusters that do not handle variations in visual appearance of the patterns very well. Our method is simpler, yet incorporates high level features implicitly. As such, we can demonstrate detections of repetitions with strong appearance variations, organized on a nearly-regular axis-aligned grid Results show robustness and consistency throughout a varied database of more than 150 images.
 Presented by O. Mattausch at the SPIE Medical Imaging 2017 conference, Orlando, Florida, USA.
In proceedings of the SPIE Medical Imaging 2017 conference.
Presented by O. Mattausch at the SPIE Medical Imaging 2017 conference, Orlando, Florida, USA.
In proceedings of the SPIE Medical Imaging 2017 conference.
Navigation and interpretation of ultrasound (US) images require substantial expertise, the training of which can be aided by virtual-reality simulators. However, a major challenge in creating plausible simulated US images is the generation of realistic ultrasound speckle. Since typical ultrasound speckle exhibits many properties of Markov Random Fields, it is conceivable to use texture synthesis for generating plausible US appearance. In this work, we investigate popular classes of texture synthesis methods for generating realistic US content. In a user study, we evaluate their performance for reproducing homogeneous tissue regions in B-mode US images from small image samples of similar tissue and report the best-performing synthesis methods. We further show that regression trees can be used on speckle texture features to learn a predictor for US realism.
Premiere at the Xenix movie theater, May 19th, 2017, Zürich.
about this video production on August 2nd, 2017 in Los Angeles, California, USA.
VarCity - The Video showcases some of the buildings blocks of creating an entire city from images.
VarCity was a 5-year research project financed by the European Research Council and obtained by ETH Professor Luc Van Gool in 2012. After 5 years of research at the Computer Vision Lab, ETH Zurich, it resulted in over 70 research papers published in top-tier conference of Computer Vision and Graphcs. We summarized the achievements in a documentary video.
Details can be found on the VarCity website and on IMDB.

 (Supplemental material here)
Presented by K. Vanhoey at the Computer Graphics International 2015 conference, June 24-26, Strasbourg, France.
Acceptance rate: 21%.
The Visual Computer, vol. 31, issue 6-8. (Proceedings of Computer Graphics International 2015)
Impact factor: 1.29 (source: ResearchGate)
(Supplemental material here)
Presented by K. Vanhoey at the Computer Graphics International 2015 conference, June 24-26, Strasbourg, France.
Acceptance rate: 21%.
The Visual Computer, vol. 31, issue 6-8. (Proceedings of Computer Graphics International 2015)
Impact factor: 1.29 (source: ResearchGate)
View-dependent surface color of virtual objects can be represented by outgoing radiance of the surface. In this paper we tackle the processing of outgoing radiance stored as a vertex attribute of triangle meshes. Data resulting from an acquisition process can be very large and computationally intensive to render. We show that when reducing the global memory footprint of such acquired objects, smartly reducing the spatial resolution is an effective strategy for overall appearance preservation. Whereas state-of-the-art simplification processes only consider scalar or vectorial attributes, we conversely consider radiance functions defined on the surface for which we derive a metric. For this purpose, several tools are introduced like coherent radiance function interpolation, gradient computation, and distance measurements.l Both synthetic and acquired examples illustrate the benefit and the relevance of this radiance-aware simplification process.
 (Supplemental material here)
Presented by Adrien Bousseau at the Eurographics Symposium on Rendering 2015 conference, June 24-26, Darmstardt, Germany.
(Supplemental material here)
Presented by Adrien Bousseau at the Eurographics Symposium on Rendering 2015 conference, June 24-26, Darmstardt, Germany.Recent color transfer methods use local information to learn the transformation from a source to an exemplar image, and then transfer this appearance change to a target image. These solutions achieve very successful results for general mood changes, e.g., changing the appearance of an image from ``sunny'' to ``overcast''. However, such methods have a hard time creating new image content, such as leaves on a bare tree. Texture transfer, on the other hand, can synthesize such content but tends to destroy image structure. We propose the first algorithm that unifies color and texture transfer, outperforming both by leveraging their respective strengths. A key novelty in our approach resides in teasing apart appearance changes that can be modeled simply as changes in color versus those that require new image content to be generated. Our method starts with an analysis phase which evaluates the success of color transfer by comparing the exemplar with the source. This analysis then drives a selective, iterative texture transfer algorithm that simultaneously predicts the success of color transfer on the target and synthesizes new content where needed. We demonstrate our unified algorithm by transferring large temporal changes between photographs, such as change of season -- e.g., leaves on bare trees or piles of snow on a street -- and flooding.
 (text of talk here)
(Supplemental material here)
Presented by G. Gilet at the ACM SIGGRAPH Asia 2014 conference, December 3-6, Shenzhen, China.
Acceptance rate: 18%.
ACM Transactions on Graphics, vol. 33, issue 6. (Proceedings of SIGGRAPH Asia 2014)
Impact factor: 5.70 (source: ResearchGate)
(text of talk here)
(Supplemental material here)
Presented by G. Gilet at the ACM SIGGRAPH Asia 2014 conference, December 3-6, Shenzhen, China.
Acceptance rate: 18%.
ACM Transactions on Graphics, vol. 33, issue 6. (Proceedings of SIGGRAPH Asia 2014)
Impact factor: 5.70 (source: ResearchGate)
Local random-phase noise is an efficient noise model for procedural texturing. It is defined on a regular spatial grid by local noises, which are sums of cosines with random phase. Our model is versatile thanks to separate samplings in the spatial and spectral domains. Therefore, it encompasses Gabor noise and noise by Fourier series. A stratified spectral sampling allows for a faithful yet compact and efficient reproduction of an arbitrary power spectrum. Noise by example is therefore obtained faster than state-of-the-art techniques. As a second contribution we address texture by example and generate not only Gaussian patterns but also structured features present in the input. This is achieved by fixing the phase on some part of the spectrum. Generated textures are continuous and non-repetitive. Results show unprecedented framerates and a flexible visual result: users can modify noise parameters to interactively edit visual variants.
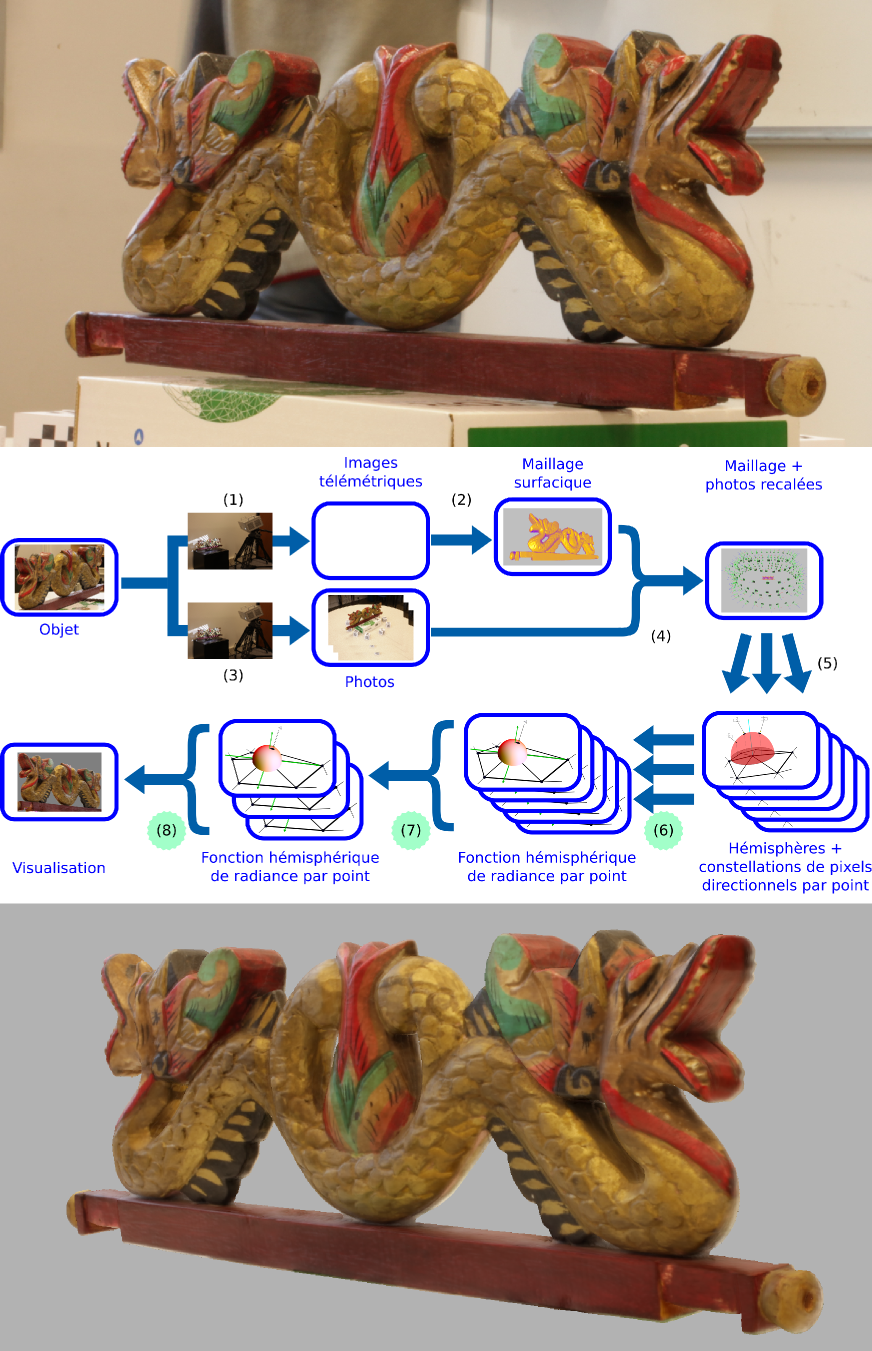 Presented publicly by K. Vanhoey at the Université de Strasbourg on February 18, 2014.
Presented publicly by K. Vanhoey at the Université de Strasbourg on February 18, 2014.
Vision and computer graphics communities have built methods for digitizing, processing and rendering 3D objects. There is an increasing demand coming from cultural communities for these technologies, especially for archiving, remote studying and restoring cultural artefacts like statues, buildings or caves. Besides digitizing geometry, there can be a demand for recovering the photometry with more or less complexity : simple textures (2D), light fields (4D), SV-BRDF (6D), etc. In this thesis, we present steady solutions for constructing and treating surface light fields represented by hemispherical radiance functions attached to the surface in real-world on-site conditions. First, we tackle the algorithmic reconstruction phase of defining these functions based on photographic acquisitions from several viewpoints in real-world "on-site" conditions. That is, the photographic sampling may be unstructured and very sparse or noisy. We propose a process for deducing functions in a manner that is robust and generates a surface light field that may vary from "expected" and artefact-less to high quality, depending on the uncontrolled conditions. Secondly, a mesh simplification algorithm is guided by a new metric that measures quality loss both in terms of geometry and radiance. Finally, we propose a GPU-compatible radiance interpolation algorithm that allows for coherent radiance interpolation over the mesh. This generates a smooth visualisation of the surface light field, even for poorly tessellated meshes. This is particularly suited for very simplified models.
 Computer Graphics Forum, vol. 32, issue 6.
Impact factor: 2.68 (source: ResearchGate)
Presented (invited CGF paper) by K. Vanhoey at the 25th Eurographics Symposium on Rendering, June 25-27 2014, Lyon, France.
Computer Graphics Forum, vol. 32, issue 6.
Impact factor: 2.68 (source: ResearchGate)
Presented (invited CGF paper) by K. Vanhoey at the 25th Eurographics Symposium on Rendering, June 25-27 2014, Lyon, France.2D parametric color functions are widely used in Image-Based Rendering and Image Relighting. They make it possible to express the color of a point depending on a continuous directional parameter: the viewing or the incident light direction. Producing such functions from acquired data is promising but difficult. Indeed, an intensive acquisition process resulting in dense and uniform sampling is not always possible. Conversely, a simpler acquisition process results in sparse, scattered and noisy data on which parametric functions can hardly be fitted without introducing artifacts.
Within this context, we present two contributions. The first one is a robust least-squares based method for fitting 2D parametric color functions on sparse and scattered data. Our method works for any amount and distribution of acquired data, as well as for any function expressed as a linear combination of basis functions. We tested our fitting for both image-based rendering (surface light fields) and image relighting using polynomials and spherical harmonics. The second one is a statistical analysis to measure the robustness of any fitting method. This measure assesses a trade-off between precision of the fitting and stability w.r.t. input sampling conditions. This analysis along with visual results confirm that our fitting method is robust and reduces reconstruction artifacts for poorly sampled data while preserving the precision for a dense and uniform sampling.
 (Supplemental material here)
Presented by K. Vanhoey at the ACM SIGGRAPH Asia 2013 conference, November 19-22, Hong Kong, Hong Kong.
(Supplemental material here)
Presented by K. Vanhoey at the ACM SIGGRAPH Asia 2013 conference, November 19-22, Hong Kong, Hong Kong.In computer graphics, rendering visually detailed scenes is often achieved through texturing. We propose a method for on-the-fly non-periodic infinite texturing of surfaces based on a single image. Pattern repetition is avoided by defining patches within each texture whose content can be changed at runtime. In addition, we consistently manage multi-scale using one input image per represented scale. Undersampling artifacts are avoided by accounting for fine-scale features while colors are transferred between scales. Eventually, we allow for relief-enhanced rendering and provide a tool for intuitive creation of height maps. This is done using an ad-hoc local descriptor that measures feature self-similarity in order to propagate height values provided by the user for a few selected texels only. Thanks to the patch-based system, manipulated data are compact and our texturing approach is easy to implement on GPU. The multi-scale extension is capable of rendering finely detailed textures in real-time.
 Presented by K. Vanhoey at the
11th Eurographics Symposium on Geometry Processing, July 3-5 2013, Genova, Italy
Presented by K. Vanhoey at the
11th Eurographics Symposium on Geometry Processing, July 3-5 2013, Genova, Italy
View-dependent surface colour of virtual objects can be represented by outgoing radiance. Data resulting from an acquisition process can be very large and computationally intensive to visualise. Mesh simplification can provide a trade-off between efficiency and precision. In this paper we propose a new metric for simplifying meshes with radiance attribute through successive edge collapses. Whereas state-of-the-art simplification methods consider scalar or vectorial attributes, we conversely consider hemispherical functions. Our approach exploits a symmetrised representation of radiance functions. This enables us to define coherently distance measurement, interpolation and improved rendering, as shown by our results. Both synthetic and acquired examples illustrate the benefit and the relevance of this process.
 Présentation pour évaluation du projet doctoral à mi-parcours, Juin 2012
Présentation pour évaluation du projet doctoral à mi-parcours, Juin 2012
 Poster pour la "Journée posters" de l'école doctorale MSII, octobre 2011 à l'Université de Strasbourg
Poster pour la "Journée posters" de l'école doctorale MSII, octobre 2011 à l'Université de Strasbourg
La numérisation, notamment la numérisation d'objets d'art, est une problématique d'actualité en raison des applications nombreuses : création de contenu numérique (base de données,
créations de médias, etc.), services aux acteurs publics ou privés du secteur de l'art et des médias, etc.
Le nombre de problèmes liés à la numérisation d'objets 3D sont cependant encore nombreux. Une copie numérique fidèle doit rendre possible la restitution de l'apparence de l'objet concerné sous des conditions d'éclairage variable. Il est donc nécessaire d'acquérir non seulement sa géométrie, mais également l'ensemble des caractéristiques physiques liées à son apparence (donc sa texture, voire sa réflectance bi-directionnelle).
La très grande masse de données engendrées par les instruments de mesure est telle qu'une utilisation directe des données s'avère impossible : il faut d'une part reconstruire un objet
virtuel compressé (maillage à attributs) puis simplifier ce dernier.
Reconstruction de l'apparence de l'objet : la chaîne de traiment considérée permet de reconstruire un maillage surfacique depuis un ensemble d'échantillons de position (points 3D issus de scans géométriques de l'objet) et d'apparence (photographies permettant d'associer des couleurs à un point 3D en fonction des conditions d'observation). Il en résulte une déscription de la couleur en fonction des conditions d'observation. Le travail principal consiste à déterminer d'une part la nature de cette fonction (sa forme), d'autre part la méthode de construction de la fonction à partir des échantillons (le fitting), de façon à représenter au mieux les variations de couleur mesurées.
Visualisation : le maillage surfacique généré est volumineux et pour obtenir une visualisation temps-réel, la mise en place d'un mécanisme de choix de compromis entre rapidité et fidélité visuelle est indispensable. Une façon d'atteindre un tel compromis consiste à simplifier (approximer) le maillage et ses attributs avec perte minimale de fidélité par rapport au modèle détaillé. Il s'agit ainsi de déterminer une méthode de simplification permettant de discriminer détails (visuels) importants à préserver et détails peu visibles à approximer.
 Mémoire de master d'informatique, spécialité Informatique et Sciences de l'Image
Mémoire de master d'informatique, spécialité Informatique et Sciences de l'ImageLa restitution de modèles avec champs de lumière ajoute beaucoup de réalisme aux objets virtuels numérisés. Ils permettent de faire varier la couleur d'un objet en fonction du point de vue de l'utilisateur, ce qui permet de modéliser des reflets spéculaires notamment.
Cependant, les maillages représentant de tels modèles sont souvent très détaillés et difficiles à afficher en temps réel.
Aucune publication ne traite à ce jour de la simplification de maillages avec champs de lumière. Ainsi, nous analysons d'abord les méthodes de simplification de maillages plus simples pour ensuite les comparer et en établir un bilan.
Ensuite, nous proposons une première méthode de simplification basée sur des contractions successives d'arêtes. Pour cela, nous associons à chaque arête une mesure d'erreur locale permettant d'évaluer le biais qui sera introduit par sa contraction. Cette mesure est constituée d'une mesure d'erreur en géométrie et d'une mesure d'erreur sur les champs de lumière.
De plus, nous proposons plusieurs façons d'associer un nouveau champ de lumière au sommet résultant d'une contraction d'arêtes.
 Actes des 23èmes journées de l'Association Française d'Informatique Graphique, 17-19 novembre 2010, Dijon
Taux d'acceptation : comité de relecture sans avis d'acceptation
Presenté par K. Vanhoey à la conférence AFIG 2010, 17-19 novembre 2010, Dijon, France.
Actes des 23èmes journées de l'Association Française d'Informatique Graphique, 17-19 novembre 2010, Dijon
Taux d'acceptation : comité de relecture sans avis d'acceptation
Presenté par K. Vanhoey à la conférence AFIG 2010, 17-19 novembre 2010, Dijon, France.
La demande pour un rendu réaliste d'objets numérisés est conséquente, notamment dans le domaine de l'art ou de la préservation du patrimoine. Pour garantir ce réalisme, il est utile d'ajouter aux modèles surfaciques non pas uniquement de la couleur, mais des champs de réflectance. Ceci génère cependant des modèles complexes et difficiles à rendre en temps réel, d'où ressort une nécessité de simplification.
Alors que la simplification de maillages sans attributs ou avec attributs vectoriels (couleur) a été fortement étudiée, il n'existe aucune méthode de simplification pour des modèles à attributs fonctionnels tels que des fonctions de réflectance ou des champs de lumière surfaciques.
Dans cet article, nous proposons une première méthode de simplification de modèles polygonaux avec champs de lumière basée sur des contractions d'arêtes. Nous définissons une mesure d'erreur locale permettant d'évaluer le biais introduit par une contraction d'arête en termes de géométrie et de champs de lumière. Nous proposons par ailleurs plusieurs façons d'associer de nouveaux attributs au modèle simplifié.
Finalement, nous comparons les méthodes proposées sur deux modèles afin de mettre en avant les caractéristiques de chacune d'entre elles.